Porcessing Production logs using Python and SQL
In a seismic acquisition survey all of the field and processed seismic data are held digitally on removable or external hard drives. Back to the base camp this data and ancillary field data will be analysed and QCed properly.
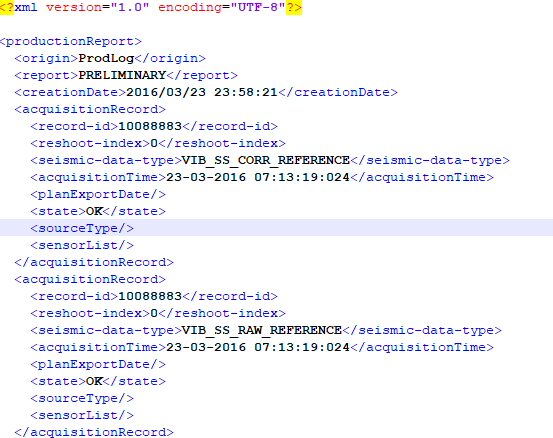
One of the most important ancillary field data that we receive is called “Oberver Log”, it contains all the necessary information we need about the records (SEG-D files). All the details are specified in this report, such as missed shots, bad traces, noisy shots. In addition, some recording systems generate what is called a production log in XML format, including the information of the acquisition records, data type (correlated or uncorrelated), time stamp, reshoot status…etc.
The production log is generated automatically from the recording unit and it’s in XML (Extensible Markup Language) format which makes the QC task difficult.
For this reason, I generated a python code using ElementTree Python module and SQL to parse the information, process it and then output it in an excel file from the SQLite database file.
1. What is XML format?
The Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
2. Create a new SQL database
First of all we need to create and connect our SQL database containing the information we need:
import xml.etree.ElementTree as ET
import sqlite3
conn = sqlite3.connect('prodlog_xml_db.sqlite')
cur = conn.cursor()
# Make some fresh tables using executescript()
cur.executescript('''
DROP TABLE IF EXISTS Record_id;
CREATE TABLE Record_id (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
record_id INTEGER,
reshoot_idx INTEGER,
data_type TEXT,
state TEXT,
Date TEXT
);
''')
2. Parsing the XML file
In this step we parse the information of the XML file (the production log) only the attributes we need.
Python code
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Production-Log-23-03-2016-23.58.20.xml'
stuff = ET.parse(fname)
all = stuff.findall('acquisitionRecord')
corr=[]
for item in all:
if item.find('seismic-data-type').text == 'VIB_SS_CORR_REFERENCE':
corr.append(item.find('seismic-data-type').text)
#print('CORR FILES:', len(corr) )
for item in all:
if item.find('seismic-data-type').text:
data_type = item.find('seismic-data-type').text
if item.find('state').text:
state = item.find('state').text
if item.find('reshoot-index').text:
reshoot_idx = item.find('reshoot-index').text
if item.find('record-id').text:
record_id = item.find('record-id').text
if item.find('acquisitionTime').text:
date = item.find('acquisitionTime').text
if data_type is None or state is None or reshoot_idx is None or record_id is None or date is None:
continue
2. Parsing the XML file
The last step will be to insert the attributes information parsed from the XML file to our new database then you can view the datbase using any SQL software. In my case, I explored the generated database using SQLite.
You can even export the information in Excel file.
Python code
cur.execute('''INSERT OR REPLACE INTO Record_id
(record_id, state, data_type, reshoot_idx, Date)
VALUES ( ?, ?, ?, ?, ?)''',
( record_id, state, data_type, reshoot_idx, date) )
conn.commit()
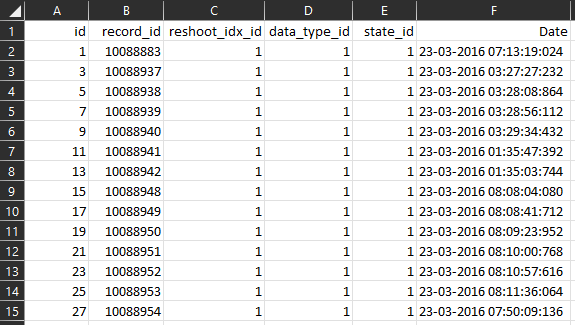
Below and example of the exported data from the SQL database into an Excel file showing in details the id, the acquisition id, reshoot status, data type and the time stamp.